Roles? Those are claiiiiiims!

[Warning: if you are not an identity geek, don’t read]
People tend to approach new things by understanding how they relate with what they already know. That’s natural, and that’s also a very effective strategy: however it can only get you so far, and if you don’t start thinking out of the box/venture in uncharted territory you risk getting stuck in a local maxima. That’s exactly the case with roles and claims: if you read the growing corpus of literature on the subject of claims based access, you’ll often see claims positioned as a little more of mere vehicles for roles (when they don’t get confused with privileges, that is). What’s worse, that is usually not positioned just as an example of common usage: from the text you sometimes have the impression that claims are understood as roles in disguise, which may end up creating artificial boundaries that are simply non-existent and cripple the entire thing. Imagine a bunch of people that are able to count only with integer numbers: for them, 6 cookies / 2 people == 3 cookies each and 7 / 2 == 3 and some negotiation skills for assigning the 1 cookie left. Now, imagine that somebody introduces them to the floating point notation: that’s a great step forward, but if you don’t explain also the concept of rational numbers that won’t be of much use for tacking new challenges: they’ll correctly write 6.00 / 2.00 = 3.00 but they conclude that 7.00 / 2.00==3.00 with 1.00, which is tragically missing the point! Well, that disturbs me enough to disregard the projection of the awesome Wall-E (I’m on a flight from Seattle to Paris) and spend few hours giving you my 2 cents on the subject. Note, I am not proposing that you use this directly for explaining claims to the non-initiated; not at all. This is for discussing with you, the initiated, why I believe that explaining claims only in term or roles is limiting. Think of this as a demonstration of a theorem: you don’t need to know it for using the corresponding property, all you need is the thesis.
Roles & RBAC: a Primer
Before my usual pontification, back to basic: what are roles? Roles represent a very powerful approach to access control management, they are pretty well known by developers (though often not very thoroughly understood, since it’s easy to stop at the first intuitive grasp of them), and they are practically rule 34 for system administrators since they dramatically simplify their work. I am sure you already know everything about it, hence you can safely skip this section: or, if you feel like going back to basics and giving a fresh new look, feel free to join the ride.
Role based access control, or RBAC, shows up on the computer security scene in the early 90’s. At the time there just 2 known approaches to system security (still in use to present day): MAC and DAC. MAC and DAC are pretty ancient stuff: they were formally introduced in 1983 in a document from the US Department of Defense, the famous “Trusted Computer System Evaluation Criteria“. I’m not an expert on this, but just for giving some background:
- MAC, or Mandatory Access Control, is the tightest approach. In a MAC regime, there is a single entity which decides (via policy) the outcome of every single access attempt to any kind of resource. That’s typically associated to military applications, as hinted by some of the language commonly used in this context: objects have a level of sensitivity, represented by a label, subjects have clearance levels, and so on. MAC systems are as tight as it gets, at least in the cases in which implementers try to give justice to the “mandatory” part, but they impose a heavy administration burden: a single admin has to micromanage everything, a toll that you are probably not willing to pay unless the price of even a single unauthorized access is unacceptably high (as it is the case in military applications). Also, “mandatory” is a pretty big word: how do you prove that your checks are indeed mandatory? For may systems the main point is indeed the last one.
Naturally, you could apply MAC just to portions of your system: for example, Vista & Windows Server 2008 implement something of the sort here and there (ever tried to launch an exe downloaded from the internet? The little extra dialog you get for confirming execution is a consequence of the “integrity level” that those apps are assigned by a MAC-type subsystem) but they implement other strategies elsewhere. - DAC, or Discretionary Access Control, is instead based on the identity of the subject that is requesting access to a resource (identity here is not meant as “a set of attributes of a subject”, it represents being exactly THAT user/account/group/etc). The approach is said to be discretionary because a subject can decide to transfer/grant access rights to other subjects. That allows a number of interesting tricks, such as introducing the idea of owner of a resource who can administer it by granting access rights to others, which can make systems much easier to manage since sys admins can be out of the loop in many cases. DAC is much more agile than MAC, hence enjoyed much wider adoption outside the military circles. One typical remark you’ll hear about it is that while MAC will try to prevent unauthorized access at all costs, with DAC you can’t possibly do that hence you focus on leaving an audit trail so that if some wrongdoing happens you can trace back the perpetrator.
RBAC is introduced in 92 (by Kuhn & Ferraiolo) as alternative to both MAC and DAC. The idea is pretty simple. F & K observed that very often users do not really own the objects they manipulate, as certain interpretations of DAC would instead suggest: in fact, those objects are owned by the organization they belong to (ie the user’s employer), and a user has access to them in the measure that his or her job function entails. You work in HR, you have access to employee’s record; you are the director of a group, you get to perform budget decisions; ad so on. The beauty of the approach is that it can model aspects of the business, hence yielding results that “make sense”. In practice, consider the following oversimplified recipe:
- List the various job functions in our organization: those will be your roles
- For every job function, determine what operations should be performed as part of the corresponding job function and codify those in a suitable set of permissions associated to the role
- Assign roles to your users, according to job function. A user can have more than one role, and every role most definitely can be assigned to more than one user
Et voila’! The business rules that were already established in the meatspace are now enforceable online, saving you a lot of thinking (or, to be precise, re-thinking). However try not to fall in the trap of considering roles equivalent to groups. A group is a set of users, a role is a set of permissions: it is often handy to associate the two, but it is not always the case.
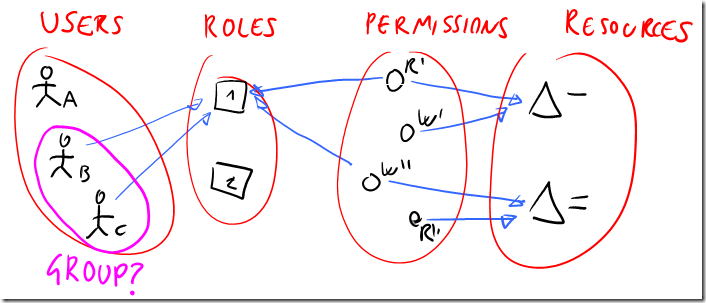
How is this RBAC different from MAC and DAC? The “discretionary” is gone here, being in a role does not usually imply being able to gift the same role to other users; hence, RBAC != DAC (or better, DAC could be simulated via RBAC). The comparison with MAC is trickier: if while using RBAC I create roles called “clearance levels” and I codify the associated privileges in term of sensitivity, I get something that looks pretty darn like MAC to me. I know that there is a formal demonstration which shows that indeed MAC, DAC and RBAC are all different; however I suspect that it would require more rigorous definitions than the informal ones I’ve given so far, hence we’ll ignore those fine differences here. The main difference I’d point out is that probably people talks of MAC when the granularity of the target entities is fine (files, threads, ports, db entries) and the modes though which systems check deserve the “mandatory” attribute; while RBAC lives at a higher level, where business entities are already recognizable: which is a great segway to the next thing I want to say about roles.
The description I gave above is a bit of an oversimplification: on one hand it is not always easy to find such direct correspondence between jobs and roles (as defined above), on the other there is the fact that roles are useful in many, maaaany more scenarios than simple job function mapping (which in fact is kind of the frictionless problems you do the first few months of the Physics I class). Take content management systems: do words like “contributor”, “reader”, “owner” ring a bell? Those are definitely roles: but instead of corresponding to something defined at the organization level (“HR FTEs”, “Managers”) it is a concept specific to the nature of the resource. Content management systems work in a way for which it just makes sense to group certain sets of permissions together: such groups have meaningful names which make great roles (my INeologismFactory attitude would make me say that those are “content management archetypes”). This is just great for administrators, which can now assign roles instead of worrying about managing single individuals: or is it? Should you have a global, enterprise-wide “contributor” role or should you have different versions of “contributor” corresponding to all the different apps & packages (& different permissions sets required) in your portfolio? How to accommodate in your strategy those products and OSes in your enterprise which already have their roles systems? How do you decide if you should spawn a new role or reuse an existing one? How do you even find out if a suitable role already exists in your enterprise before you spawn a new one?
Ok, I did digress: anyway, with the above blabbering I hope I managed to 1) give you a bit of background on what RBAC is 2) give a vague idea of what it can accomplished with it and 3) hint at the fact that applying RBAC as a strategy may be less easy that one would be tempted to think. Now we established a baseline and hopefully we all mean the same thing when we say RBAC.
Roles & Claims
A claim is a statement made by one subject about another subject.
How many times have you heard this definition? It’s beautiful in its simplicity: and really, it’s all there is to know . Everything follows via common sense.
[Note: as Einstein said, “Everything should be as simple as it is, but not simpler”. Surprisingly, somebody describes claims just like key-value pairs and disregard the claimant part: needless to say, if you think in those terms you can make some serious mistakes in defining architectures and deriving properties, hence I would not advise that.]
What can a subject say about another subject? Anything, really. It could be A) a property/attribute intrinsic to the subject (name, birth date, my favorite “hair length, the FI team favorite “shoe size”, etc. Not to be confused with PII); it could B) express a capability/permission/privilege in relationship to a resource (“can call VoterPhone method”; “can publish a service on the ServiceBus”; “can read from \machineshare”; etc); it could C) express aspects of a relationship that ties the subject to other subjects or artifacts (group membership being the natural example); nothing more comes to mind right now, but I am sure that there are many other cases. Let’s just play with those three, I am sure they’ll be enough to make the point.
Claims are so much more than roles
Let’s get back at our original problem, the fact that often claims are positioned just as a new way of implementing RBAC. At a fist glance, I’d say that of the three kinds listed above only C is a good candidate for transporting role information. Would you say that A and B are less interesting, then? Good luck defending that position. A is clearly key in consumer scenarios, but is by no mean limited to that (“spending limit” could be an A). B is extremely important, because it represents the result of an authorization process and is easily enforceable by the infrastructure for allowing/disallowing access to resources without requiring explicit attention from the code of the resource itself; in fact, B types are indeed mentioned but somewhat arbitrarily classified as RBAC too.
Ok, so A and B are interesting too. But do we really need to talk explicitly about them, can’t we just derive their properties and the relative practices from a description of C? I don’t believe so, and for solid architectural reasons. A, B and C are typically originated in different nodes of a distributed system. A will come from an IP role, an entity which knows directly about the subject; B will be the result of logic run at an authorization decision point, which clearly must know about the resource (and may or may not have a direct relationship with the subject; in a federated scenario, that is not the case); C is somewhat similar to A, with the additional element brought by the need of a context (the issuing authority must know both about the subject and about the entities which which he/she/it is in relationship with: more like an directory (which knows both about users and resources) than a government-management citizen’s attributes store).
Below there’s a little sketch exemplifying the above. The leftmost element is a pure IP, generating A-type claims; the rightmost is an IP issuing C-type claims, which in fact uses a directory as its store; in the center we have a B-type generator, which typically will apply rules for deriving B-type claims from sets of As and Cs (and possibly Bs as well). The interesting difference between A&C and B is that while the formers store info about subjects (attributes and relationships, respectively), the latter stores info about claims (how to transform them). Architecturally speaking, this is a key factor for determining which claims you can extract from what and the kind of maintenance you have to foresee. Of course you can have “degenerate” cases in which you assign permissions directly to subjects, in which case B will have a dependency on accounts too. But I’m digressing again.

Not only the sources are different, chances are that the RPs will consume different claim types in in different ways: while “name” may be used both for personalization or authorization, a permission will almost always (ie by definition) result in an authorization enforcement. Which of course implies that the places in your solution where you’ll consume the claims will likely be different: “name” could be used by the presentation layer, while a permission will likely be processed by the dispatching infrastructure rather than the resource’s code (see below for a little sketch of how a token containing both A and B may be processed).

Bottom line: the rabbit hole is so much deeper than the simple “transport-roles-independently-from-credentials-type” value prop would suggest.
Roles are in the eye of the beholder
The above should IMHO be sufficient to make the point, but we can go further.Is there a magic sauce that makes a role… a role?
Consider the Users-Roles-Permissions-Resources diagram I added in the RBAC primer, and adapt it to a scenario in which we have users in one organization accessing resources hosted by a federated partner.
A user goes to his own IP, and gets a token for accessing the other organization: that token will likely contain A and C types. Can it contain B types? Not really, because in general the origin IP does not know about the resource, and it is not authoritative about it: if a federated partner would allow external authorities to emit permissions for its resources that would not be trust, that would be the equivalent of giving away its power of attorney :-). So just As and Cs.
The FP receives the token. Let’s say that it contains the claim “group:remote debuggers”. For the originating organization, this is clearly a C-type and possibly a role: but what about the target organization? Will the target organization recognize it as a role? There’s nothing intrinsic in it that screams “I’m a role”, or even if there is that does not necessarily make it relevant for the kind of resources handled by the target organization. If you want that claim to map in a role claim in the target org, you need to provide that rule explicitly. That works also in the opposite sense. For the originating org “citizenship:US” may be just a A type, while for the target org (perhaps involved with some national security activity) this may actually be a role with well defined permissions associated to it. In summary: what is a role at origin may not be a role for the target, and vice versa.
It gets better. Would you expect the FP to issue B claims? It’s already hard to keep track of the roles of you own org; managing role mapping with other orgs complicates things further. Chances are that at least for some apps you’ll hand to handle the roles-permissions mapping at the app (or apps set) level, so that you don’t pollute further the schemas at the org scope level; that would also keep reasonable the number of claims you’ll get from the FP. That means more flexibility & independence in managing things.
Bottom line: describing every claim in term of role does not give a set of stable properties you can count on, if you are working across multiple orgs or you cross management boundaries in general. What were we using claims for, again?

Doing things just out of habit
How do you decide if a user from another org belongs to a certain role in yours? If you are lucky, it is possible to define a mapping between a set of incoming claims and a resulting role: grand vizir->administrator. However it is not uncommon that all your existing roles grants too much or too little permissions than you’d want to give in that case. The classic reaction would be to create a new role with the desired permissions set, then write the logic that assigns it if the set of incoming claims is right. An administrator would like it, because it gives a visible moniker to that set of permissions. But what happens if the number of times you have to do this skyrockets? There’s a point of diminishing return in which the sheer number of roles you need manage trumps the advantages; if you have many partners and your relationships change fairly often, that number may not be too far. Furthermore: the same reasoning can be applied to the applications portfolio inside an organization. Every app will have different authorization needs, and the claims coming from company directory scope may not be describing exactly what is needed for the specific resources handled. If you use claims, you have a solution handy: instead of using mapping logic for assigning a role and then resolve the associated permissions, you can use the same mapping logic for granting directly the permission set you want. In short, you’d go directly A->B without going through an artificial role.This is especially applicable if you own the subsystem you are working with (ie the application itself) and/or if the decisions you want to make are fairly transient (ie you use Nationality and Age for determining if a caller can invoke the usual WineSelling service, but you’d have no other company-wide use for a PotentialDrinker role). I am not saying that all that mapping login will not need to be managed: but externalizing it in R-STSs makes the job feasible, and especially it lets application and sub-scopes owners manage it instead of polluting the global set.
Bottom line: always reasoning in term of roles may sometimes invite the creation of artifact roles that in fact are unnecessary if you are using claims and that can worsen the noise/signal ration in the already challenging task of keeping enterprise roles management under control. Ok, that sentence could have used a comma somewhere.
Claims are not (just) roles
A claim is a statement made by one subject about another subject. That statement can certainly be “I, subject X, state that the current subject belongs to the role contributor“; but it can be also many other things, like “I, subject X, state that the current subject is Belgian” or “I, subject X, state that the current subject can invoke the VoteForPhone service“. The implications of those differences deserve to be explored if you want to understand how to best take advantage of this. Different type of claims will be consumed in different ways, from different parts of the architecture; and nature of the information contained in it will determine from which entities we can expect which kind of claims, giving some indication on how we can leverage our assets for achieving our goals in the best possible way.
Roles are super-useful, well established and extremely powerful. Understanding how claims can be used with RBAC is of key importance: however implying that claims are just a technology-independent mechanism for transporting roles means forsaking a lot of the power they offer. And that would be a pity, wouldn’t it 🙂
One Comment