The Tao of Authentication (Part III – last)
(continues from Part I and Part II)
Finally we’ve lined up all the elements we need for understanding how we can get rid of the 1-2-3 tyranny, and deal with our business requirements directly instead of relying on an old model that forces us to perform unnecessary steps and introduces artificial dependencies.
For making sense of what I write in this post you *really* need to read part I and II as well; without the right context, some of those things could be badly misinterpreted. Sorry 🙂
Outsourcing user authentication
As much as I’d like to think that everybody is super interested in authentication, reality is that you may care very little about it. Let’s say you are hosting your own blog, and comment spammers harass you. You can make their life more difficult by adding an authentication step, that will ask your readers to sign in before being able to comment. That’s not a perfect system, but you know… security is a ladder. If you discouraged 70% of the spammers, you already made a great job. Or did you? Now you need to set up the authentication system, and above all maintain it. That means handling lost passwords; attacks to your credentials store, which may (read: will) contain passwords (well, hopefully hash derivations) your users are reusing with websites which feature higher value transaction; and many other annoyances. The blog example is a bit extreme on the low value gamut, but there are many other situations in which owning direct credentials authentication may be more of a pain than a gain: large-audience websites that are doing mainly layout customization or little more are another obvious candidate, take your pick.
Well, good news everyone! You don’t need to own the credentials authentication process if you don’t want to. There are services in the cloud that will take that headache away from you: they’ll do whatever they deem necessary for verifying if a user is a returning user according to THEIR credentials store, and if it so they’ll give you an artifact (usually a token) with which they certify that the user successfully signed in in their systems. In Fig 7 I got rid of the credentials store on premise, and I’ve added one in the cloud. The only thing left for you to verify is the source of that artifact: you want to make sure that the artifact is actually coming from the authentication service you decided to lean on, and not from some malicious pretender. You are still authenticating something, the source of the artifact: but in a certain sense, it’s like if you’d be authenticating always the same “user”. Perhaps the authentication service sends you a token signed with his private key, and you verify that signature using the corresponding public certificate you acquired at some earlier time: that looks like verifying credentials to me, even if not properly user credentials.
Now we finally see why I insisted in distinguishing the credentials verification from user lookup. You may not be interested in the pains of maintaining a user credentials verification system, but you are certainly interested in answering the famous questions about the users we begun with. At this stage, the trick is still to maintain a user profile in your attribute store; but if the only credential we verify is the one that identifies the authentication service itself, regardless of which user is coming in, how can we fish out the right record from the profile store? Well, it’s simple: the artifact we get needs to contain a handle independent from the credential mechanism, some unique (in our context) indicator of which user performed a successful login. Not rocket science? Perhaps. But the choice of the criterion with which that handle is generated can have important consequences (few keywords for the identirati reading this: PPID, linkage, usernames vs emails, i-names, liveid handles…).

Fig 7 – Credentials verification in the cloud: authentication services
The architectural pattern I described here is all but abstract. You want a couple of examples? LiveID. OpenID. Both services provide credentials verification that you can leverage for relieving yourself from the burden of maintaining a user credentials authentication system. Before somebody has the temptation of ripping his clothes in outrage and try to mob me: both LiveID and OpenID can do MUCH more for you than sheer outsourcing of authentication, here I just happen to concentrate on that specific aspect for making my point.
At this point I can almost hear some of you asking: “but Vittorio, are you telling us about identity providers here?”. And at the cost of going against popular belief, I’d say no, no, NO. Or at least, not when considered from this angle.
I have to break my little “no identity talk” embargo here. Identity, as perceived by its “bearer”, is a collection of facts about himself or herself (or even itself). Here what we are getting are CREDENTIALS, or actually the lack thereof. We are getting the certification that user credentials were successfully used at some point, and here that’s all we are interested into (remember, we are answering the “are you a returning user” question here). That’s not identity IMHO.
More questions? Bring it on. “But Vittorio, the handle for retrieving the profile may be a username, an email address; aren’t those pieces of identity?”. Well, I am not sure. For 2 reason. One is that if beauty is in the eye of the beholder, identity is in the eye of the relying party. Right, that was cryptic: let me explain. If I am using the string you are giving me as a way of looking you up in my attributes database, I really don’t care if that string contains your name, a meaningless series of characters, the answer to the most important questions about the universe (that would be “42”, BTW) or a rhymed description of the your most valuable PII. In fact I just care that such a string is unique in the context of MY site, and (let me drop a generic principle here) the more it has sense in other contexts (like a good piece of identity would) the more it is a bad idea to use it in this way (think SSN, American reader). The omnidirectional identifiers are a very special exception to this, more about that in some later post.
The second reason is admittedly less solid, and more of my gut feelings plus being a strongly opinionated jack***, but the blog is mine and I’m writing this late at night so I’ll tell you anyway. Did it ever happen to you to sign up for a service, and discover that the username you wanted to have is unavailable? “I’m sorry, the ‘vibro’ nickname is already taken. Please choose another nickname, or pick among ‘vibro2597’, ‘vibro_xp’, ‘vibrovibro’…”. Let me tell you, if I settle for ‘vibro2597’ it’s not because i have a strong feeling that it expresses well my individuality; it’s because the service I am signing up for needs a unique handler for the mechanism it uses for managing user authentication. Is it the only way? No. It’s just the way auth was handled so far. I need a handle for retrieving the right line in the attributes store, allright, but it does not need to be the nickname. I won’t go into further details here, but I can assure you it can be done and it’s not even that hard. It’s enough to have very clear the distinction between credentials and identity, and decide accordingly which data belong to which category.
Ok, let me take another question before I move on to the next pattern: “But Vittorio, isn’t the fact that the user CAN sign in in the outsourced authentication service an identity factoid in itself?”. I have to give you this one, the fact that I am able to sign in with LiveID implies I am a LiveID customer. The fact that I am able to sign in with SignOn.com implies I am a SignOn OpenID user. But. As I mentioned, identity is in the eye of the RP. The question we are trying to answer here is “are you a retuning user?”. To that end, the fact in itself that you are coming from SignOn or myOpenID is irrelevant; as long as I manage to find your handle in my attributes DB, I am happy and the application will unfold just the same regardless of the authentication service I took advantage of. Now: what if the question we want to answer would be “are you a customer of LiveID?”. Bingo. That would be identity, and getting a token certifying a successful LiveID sign in would have influence on the execution (for example, by granting single sign on capabilities with other Live services). But after all the discussion we made so far, you can see how this is actually a different thing (this different thing, for the record, is called federation). It’s interesting though, because it is our first example of a question different from “are you a retuning user?” that we can verify directly (i.e. checking the signature of the corresponding artifact), and this epiphany will bring us very far. For a deeper discussion about the distinction between identity and credentials check out this post; keep coffee handy 🙂
Let me write a little summary of the pattern we’ve seen here. Considering the classic 1-2-3 authentication pattern (verify user credentials – look it up its profile – use the profile for answering questions about the user), in practice what we’ve done here is outsourcing 1; there are services out there that will take care on maintaining a credential verification system for you, that you can use for getting phase 1 off your back. And that’s very handy! Anyway: when a service is used in this way, I don’t consider it an identity provider. The authentication service can be implemented as an STS, can have the potential to act as an identity provider, it can trade tokens, it can look like an IP as much as you want, I don’t care; the RP is not using it as a source of identities, but as a credential verification system.
Now: the RP may ask a different question, and the answer from the service could be exactly the same and yet have a very different effect. If the question is “are you a LiveID customer” or “do you have a valid OpenID account at SignOn.com”, the answer on the wire could be exactly the same token as before; but this time I would consider it actually identity information, and I would expect the RP to leverage it somehow beyond the sheer verification of 1 we’ve seen above. Again, identity is in the eye of the RP; and again, what we just described can be the founding stone of classic & user centered federation (but I won’t go there here or we’d get too far from the main line).
Outsourcing some information authentication
When I enter in a bar and I ask for an alcoholic beverage I’m rarely asked to produce an ID; that’s because the bartender does not really have an hard time estimating I’m well past my 21 (*sigh*). But what happens if somebody’s appearance does not give the age away so easily? As I love to point out in my presentations, my clipart guy of choice has no facial features whatsoever: no wonder that I always put him in the position of being authenticated with the most Byzantine methods :-). Well, if the bartender would like to verify by himself this information he’d be in trouble: cutting a finger and counting the circles wouldn’t work, and all the other methods would involve expensive equipment, specialized workforce, invasive harvesting methods (albeit less invasive than the method mentioned above) and ultimately a long time.
If you think about it, you’ll see that many online businesses are in the same position of the bartender. Let’s say that you’re a matchmaking startup: your site may need to ensure that a potential customer is not married. All you have is an instance of a web application running on a hoster farm, an office in downtown if you’re lucky, and a phone. How the hell are you supposed to gather that information in reliable fashion, and yet operate at internet scale for reaching profitability?
You already know how the bartender category solved the problem: he won’t uncork the booze without seeing that young-looking face of yours smiling from a plastic rectangle on your driving license or equivalent. In the terms of our discussion here, he does something very simple: instead of verifying a fact himself, he relies on the word of somebody who allegedly already verified the same fact. Bingo again! If you can find some way of doing the same for answering the question “are you married?” from the online world, you solved your problem. This idea can be applied to all the questions we neglected so far, that is to say all of them apart from “are you a returning user?”.
OK, we established that perhaps we can trust somebody else to tell us the answer to some of the authentication questions we have about our user. The key word here is trust. Again, this post is already monstrously long so I can’t go into the details here. Suffice to say that the meatspace is full of entities that, by their very nature, know A LOT about your potential users. Governments; schools; banks; medical institutions; clubs; insurances; businesses. Yes, this time I am really talking about identity providers. The government already knows if your users are married or not; the government needs to know it for its own reasons, for example for sorting out taxes, which are entirely independent from your business. Apart for extreme cases, like during social unrests or worse, the government have a reputation of doing a good job in gathering, verifying & maintaining that information. Hence you decide it deserves your trust on this matter, which means you’ll accept as true any statement the government will made about the marital status of your user. The effect on 1-2-3 can be pretty disruptive: you don’t need to cache in your on premise attribute store the answer to the question “is this user married?” anymore, because you will rely on the attribute store that the government maintain on its premises (fig 8). That can solve for you a huge headscratcher, direct verification of the facts you are interested into, and save you a lot of money/time. Now, the only problem left is verifying that the information we are receiving is actually originating from a source we trust: but that’s a problem we already solved. Remember when we introduced the authentication services and their artifact which assert that a user successfully signed in? Also then we had to make sure that the artifact came from the intended source, and we mentioned that digital signatures were an example on how to get the job done. All we have to do is shove in that same artifact some of this factlets about the user, which you may call claim if you’re so inclined, and we’ll be sure we know their provenience and we are able to decide if they’re trustworthy.
Let me make sure we give appropriate weight to the implications of this new element. Credentials, as we defined them so far, are a mechanism that allow us to answer in a verifiable way “are you a returning user?”. The combination of trust/reputation and artifact provenience verification now give us a mechanism for verifying any question. As long as we can find a source of information we can trust on a certain topic, we don’t need to verify directly by ourselves anything, anymore. That’s huge, and it shakes the 1-2-3 architecture from its very foundation. We’ll use our newfound power to challenge 1-2-3 more and more, until we’ll rip the entire thing apart for some cases.
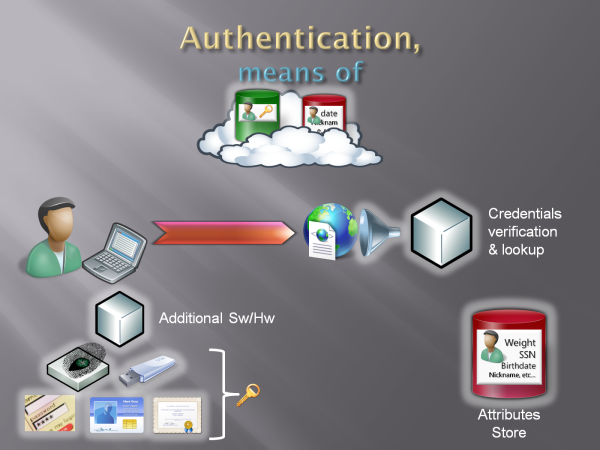
Fig 8: some attribute verification can be obtained from others in the cloud
See, from the relying party this is what claims are about. The user (subject) sees them as parts of some identity of theirs, but for the RP those are answers to questions that are necessary for conducting their business. For me the birthdate on my driving license is, well, my birthdate; for the bartender, it’s the assurance he won’t lose his license by uncorking some booze for me. Same data, very different perspectives: where I see a piece of identity, the bartender sees an answer to a question. There is another post in the Tao series which goes in fair amount of details about claims, I suggest to check it out if the topic interests you. In fact, in that post I also answer the question “But Vittorio, why in fig 8 there is an attribute store in the cloud AND the one on premise is still there?”. Let me reuse the relevant fragment of that post:
Does that mean that we should now use claims and tokens for everything, and free the hostage identity? Hmm, not necessarily. Wine is good, but water is still an appropriate drink in a lot of occasions.
Let’s say that a big online book store (bobs) decides to start accepting customers which present a token with name and shipping address issued by some big internet authority. Bobs can now clean their stores of all of the info they now receive from the authority (which is great for liability and a number of other things) and change the authentication logic accordingly. However there are still a lot of data that pertain the business that a subject makes with bobs and that cannot be provided by an external authority: the last 10 books he bought, for example. Hence the new identity context is a composition of what is received in form of claim and what is obtained by the profile, which does not disappear after all but simply can jettison the info that are better obtained from somewhere else. Should the developer know of the difference between the two info? I think so, since it really makes a difference (a date of birth gathered during some questionnaire or a date of birth certified by an authority carry different business weight); however I believe that the API should be uniform, so that information can migrate from one source to the other without disrupting too much the application.
From the above, and from other considerations, I discovered the following principle:
You want to receive in form of claims what you’d have an hard time finding out by yourself
So far that principle proved to be a useful tool when reasoning about claim based systems, especially for understanding how to change existing systems toward the new model.
Bottom line: you may still need a profile.
Last thing before I move on to the next pattern. In fig 8 I don’t have the credentials store on premise: but that does not mean that it is a necessary condition for offloading the answer to my questions to others. I may have my user credential verification on premise and still authenticate information coming from external provider. Example: you put together a home banking website, which accepts returning users by verifying their credentials directly (username+password, personal cards, both, whatever). You own credential verification. But let’s say that certain operations are allowed only if your user has a credit score above a certain threshold; you can still gather that info as needed, for example by asking for a token coming from one credit verification company; that’s attributes in the sky again.
Authentication with no strings attached
What’s the key assumption of 1-2-3? That we give a rat’s tail about knowing if the user is a returning user (I wrote it so many times that it starts to annoy me :-)). We’ve seen that sometimes we really don’t care if the user is a returning user, we just need to make sure he complies with some constraints before we give access; in classic authentication that may force us to remember every user, so that we can verify once and for all the facts about the user we are interested into and save them in a profile. That would allow us to simply bring the profile back in context every time we see that user, as opposed to perform again the verification every time he shows up. The system sucks so hard that often we just give up.
Luckily we just made a breakthrough: we found out that we can rely on others for receiving answers to our questions about our users. As long as we trust the source of our answers, we don’t even need to do security tradeoffs: we can be cryptographically certain of the source of the answer. In the former pattern we’ve seen that we can take advantage of this system for offloading the burden of the questions that are most expensive for us to answer, and keep a profile for the facts about our user that the directly own (which, by definition, are not that expensive for us to gather). Now, it is very natural to do the next step: and yet, you’d be surprised by how difficult it is for me to get some old school security expert to understand it. The next step is losing the user profile altogether. Do you think that the bartender keeps a profile for every customer? You enter, demonstrate you have a legal right to get wasted (metaphorically speaking), you sip you expensive liqueur and you’re outta there. Identity-wise, your visit is idempotent. You can go in 1 time, 300 or never, you’ll never leave a trace (unless the bartender position turnover is really low). What about the book shops in airports? The place where you go to do groceries? The hair dresser (for the ones who actually go there)? Move theaters? If you think they all keep files on you, I’m afraid that there’s a medical term for describing the situation 🙂 (unless you’re one of the guys described in this article on Wired. Being paranoid doesn’t mean that there’s nobody following you).
Once identity becomes flowing currency, you can get an answer to your questions directly; if the nature of your business does not entail returning users, customizations or transactions spanning multiple sessions the attribute store is only a nuisance. Like practically every merchant in the meatspace, you can look up the info you need in the documentation you receive (photo ID or credit cards in meatspace, tokens or similar online) and use it in the context of the current transaction. Once the current transaction is over? It’s done. The current user information goes out of scope, and the user is not current anymore. Perhaps I can keep some trace of the user identity in my records, in case something goes wrong (fraud) and in few weeks I need to understand what happened back then; but that workflow has nothing to do with authentication, and those records are not involved in subsequent visits of the same user. You can have a RP “without users”! Isn’t it great? Naturally, that is remarkably different from an “RP without customers“. You could have an RP that accepts identities from IPs which count millions of users: that simply mean that the RP does not need to remember each user for doing business with them.
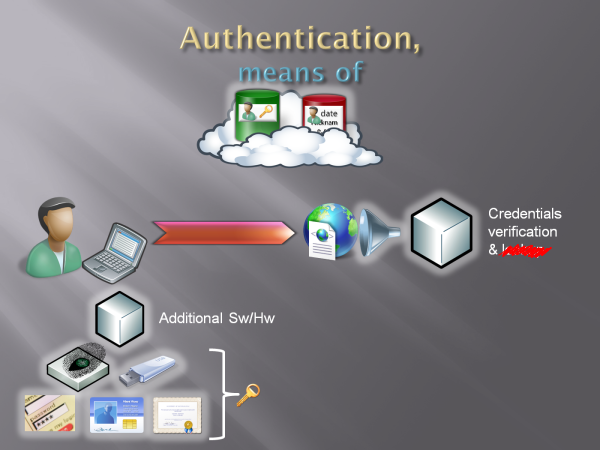
Fig 9: many business models do not include the idea of returning users; in that case, the only form of authentication required is information authentication, which can be performed without relying on credentials or attribute stores
In Fig 9 we witness the ultimate demise of 1-2-3. We don’t keep any attribute store, which now lives in the clouds. And we don’t maintain any user credentials store; I may say that it lives in the cloud as well, but that would be an Occam’s razor violation. While in the first pattern we encountered in this post I did outsource user credentials verification, here I am in a substantially different situation: I don’t care about user credentials. I can imagine that the identity providers I trust will perform some form of credentials verification, but it’s really their problem how they get their answers; as long as they send me the answers I need (read: claims in tokens) I am happy and everything else is their business. Your passport says your name is X and you’re entitled to travel, the border officer does not really worry about how your country bureaucracy verified it was really you standing in front of the counter when you went to request your document (in some case we do worry, but it’s borderline; irrelevant for the general principle).
This point is subtle but important, so I can’t let it go just yet. The website that can show you its content only after it verified you’re older than 18 can rely on a government IP for getting a claim which contains your age. What the website is outsourcing is the age verification process; but the website is NOT outsourcing user verification, BECAUSE IT DOES NOT GIVE A DAMN ABOUT WHO YOU ARE. Ahh I said it, that feels real good. So for what the website is concerned about, the green barrel in the cloud in fig 9 may or may not be there (for the record, it’s usually there); it is not a service the RP is (directly) taking advantage of. Needless to say, that describes well classic federation as well: if I land on the website of a partner of my employer, chances are that they don’t care much about me being Vittorio “Vibro.NET” Bertocci for showing the discount rate they negotiated with my company.
Mini summary of the pattern described here. The ultimate unraveling of the 1-2-3 structure comes from the realization that in certain cases A) we resort to 1-2-3 just because we need to answer certain questions, and having the answers stored in a profile is the lesser of 2 evils and B) there is a better way to get those answers on the fly, if only we leverage IPs and claims. In that case we can lose all the authentication related stores (modulo auditing) on premise, and the only task left is verifying the “IP credentials”.
Conclusions
That surely took a long time to write 🙂
In Part I we started from a blank slate and tried to understand why we authenticate users, and what do we mean by “authentication” in the classic sense of the term. We went through some of the questions we ask about users when performing access control for various typical online services. We came out with few key points:
- We answer the question “are you a returning user?” by verifying the credentials
- We link the credentials to a profile in our archive
- We “dehydrate” that profile, and we use its content for answering our other questions
In Part II we detailed what are the functional components of a generic architecture which supports the steps 1-2-3 above. We discussed what the term “credentials” mean in that context, and hinted at how it differentiates from the idea of identity.
In Part III, the post you are reading now, we got back to the original questions we had and tried to understand 3 different patterns, progressively farther from traditional authentication practices. We’ve seen what it means to outsource user credentials verification, what advantages it brings and how it is different from federation or from using identity providers. We’ve seen how we can avoid chasing the answers to our questions ourselves, and how we can rely on the knowledge of somebody we trust to already hold the right answer; we’ve explored what it means in term of extending the idea of credential authentication and offloading the attribute store. Finally, we’ve pushed the idea as far as it can get and envisioned a class of RPs where there’s no memory of specific users and no trace of on premise authentication stores.
Again, that was long but I hope you enjoyed the ride. The ones among you who made it to the end, anyway 🙂 I think I’ll often take advantage of the explanation I laid out in this triple post, so hopefully this will turn out a good investment for the both of us 😉
6 Comments